Research
Research Direction
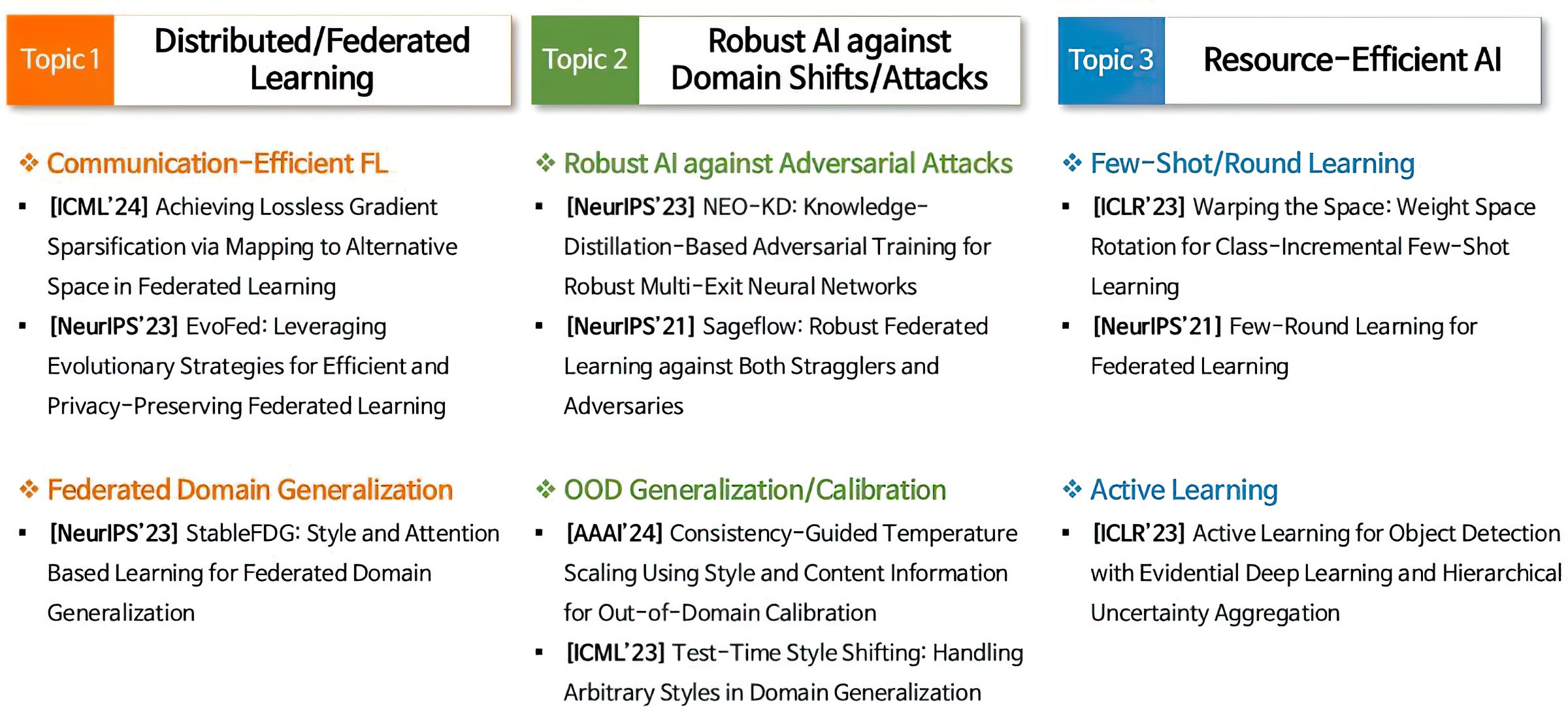
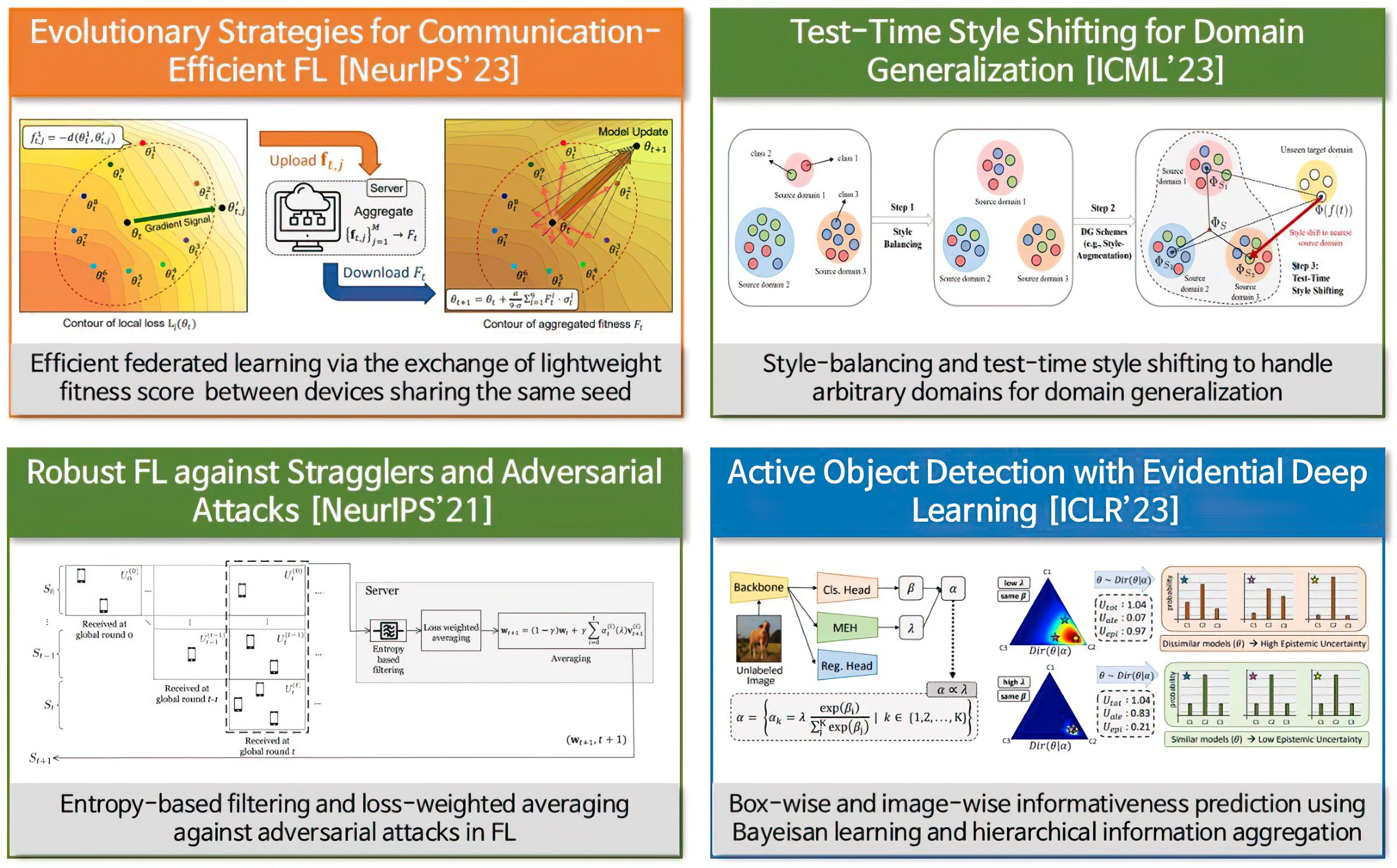
We work on distributed/federated machine learning, robust AI and resource-efficient AI, addressing all key issues in the deployment of practical AI systems

Research Direction
We work on distributed/federated machine learning, robust AI and resource-efficient AI, addressing all key issues in the deployment of practical AI systems
Copyright © Moon Lab., 2017
School of Electrical Engineering, Korea Advanced Institute of Science and Technology
291 Daehak-ro, Yuseong-gu, Daejeon 34141, Republic of Korea
School of Electrical Engineering, Korea Advanced Institute of Science and Technology
291 Daehak-ro, Yuseong-gu, Daejeon 34141, Republic of Korea